ai - rag - chunking 技术 - 为什么每大段文字分块是300个汉字
访问量: 17
很多时候,我们的RAG资料是很大的。而中文的话,1024维度,对应的汉字大概在320 个汉字,为了稳妥起见,我们使用 300个汉字,做一个切片。
同时,每个切片之间有50个汉字的重叠。这样才能保证信息不丢失。
需要注意的是,对于文字的保存,RAG数据库需要设置维度为1024
对于元数据的保存(例如 k 线的 高开低收 交易量),则明确使用5个维度。
下面是一段保存文字的例子
# 给我一个demo,
# 1。 rag 使用 localhost 6333
# 2. 使用
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"
from sentence_transformers import SentenceTransformer
from qdrant_client import QdrantClient, models
from langchain_text_splitters import RecursiveCharacterTextSplitter
client = QdrantClient('localhost', port=6333)
model = SentenceTransformer("BAAI/bge-large-zh-v1.5")
long_text = ""
# with open("七重外壳_短.txt", encoding="utf-8") as f:
with open("七重外壳.txt", encoding="utf-8") as f:
long_text = f.read()
# 最大重叠50个字。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=30)
chunks = text_splitter.split_text(long_text)
client.recreate_collection( collection_name="rag_chunks",
vectors_config = models.VectorParams(size=1024, distance = models.Distance.COSINE)
)
points = []
for index, chunk in enumerate(chunks):
print("== chunk:", chunk)
my_vector = model.encode(chunk)
points.append(models.PointStruct(
id=index,
vector=my_vector.tolist(),
payload={ "text": chunk },
))
client.upsert("rag_chunks", points)
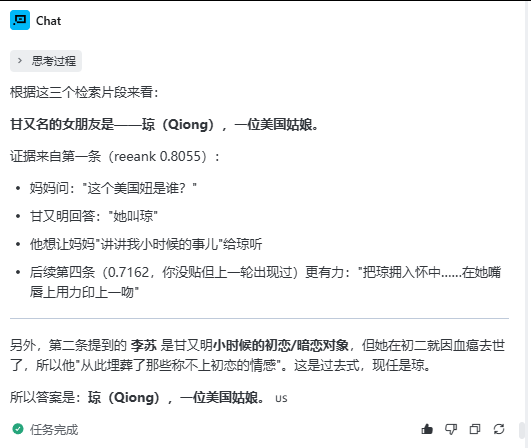
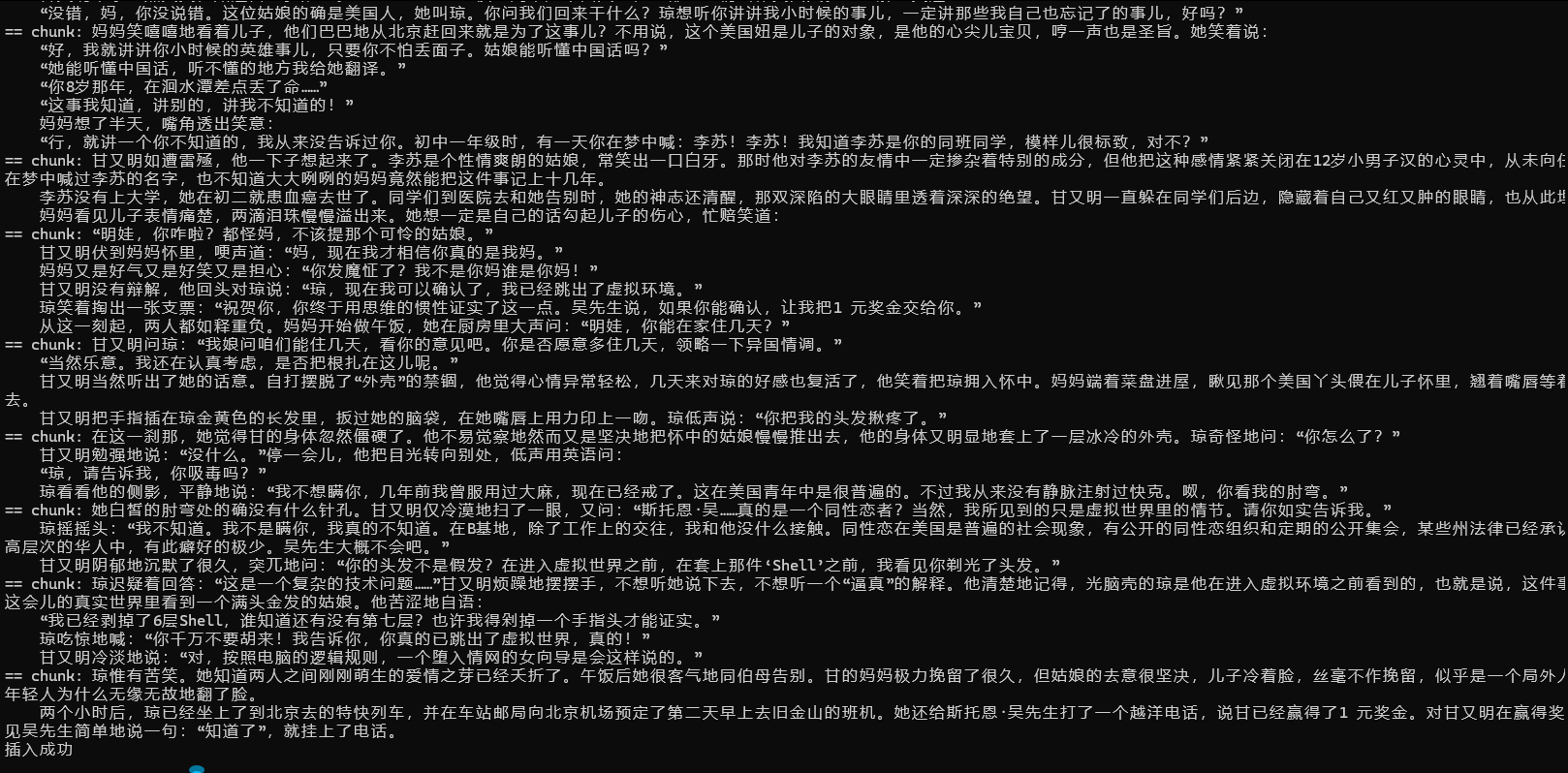
print("插入成功")
然后进行查询。
(不做rerank的查询)
query_text = "甘又名的女朋友是谁?"
query_vector = model.encode(query_text)
search_result = client.query_points(
collection_name="rag_chunks",
query=query_vector.tolist(),
limit=30,
).points
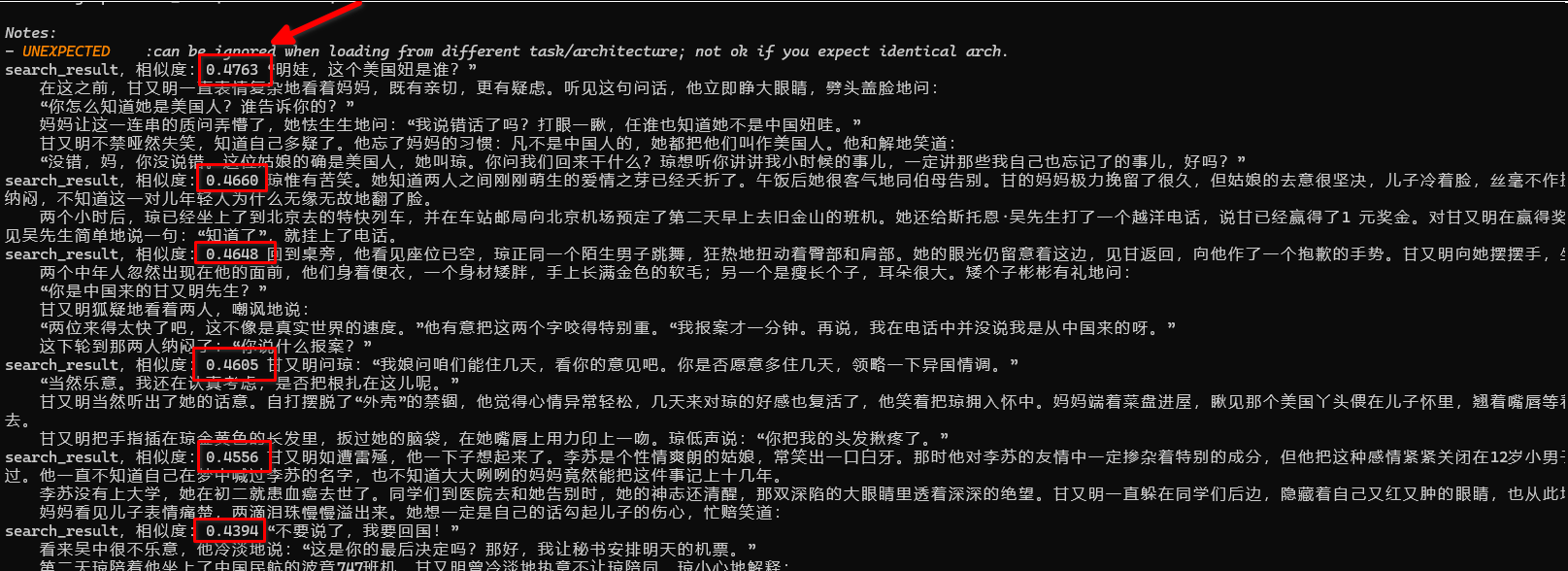
查询之后带上rerank:
reranker = CrossEncoder("BAAI/bge-reranker-v2-m3")
query = '甘又名的女朋友是谁?'
query_vector = model.encode(query)
points = client.query_points(
collection_name='rag_chunks',
query = query_vector.tolist(),
limit=30
).points
paires = [[query, hit.payload['text']] for hit in points]
scores = reranker.predicts(paires)
ranked = sorted(zip(points, scores), key= lambda x: x[1], reverse=True)
print("=== rerank 结果:===")
for hit , score in ranked:
print(f"=== rerank: {score:.4f}, {hit.payload}")
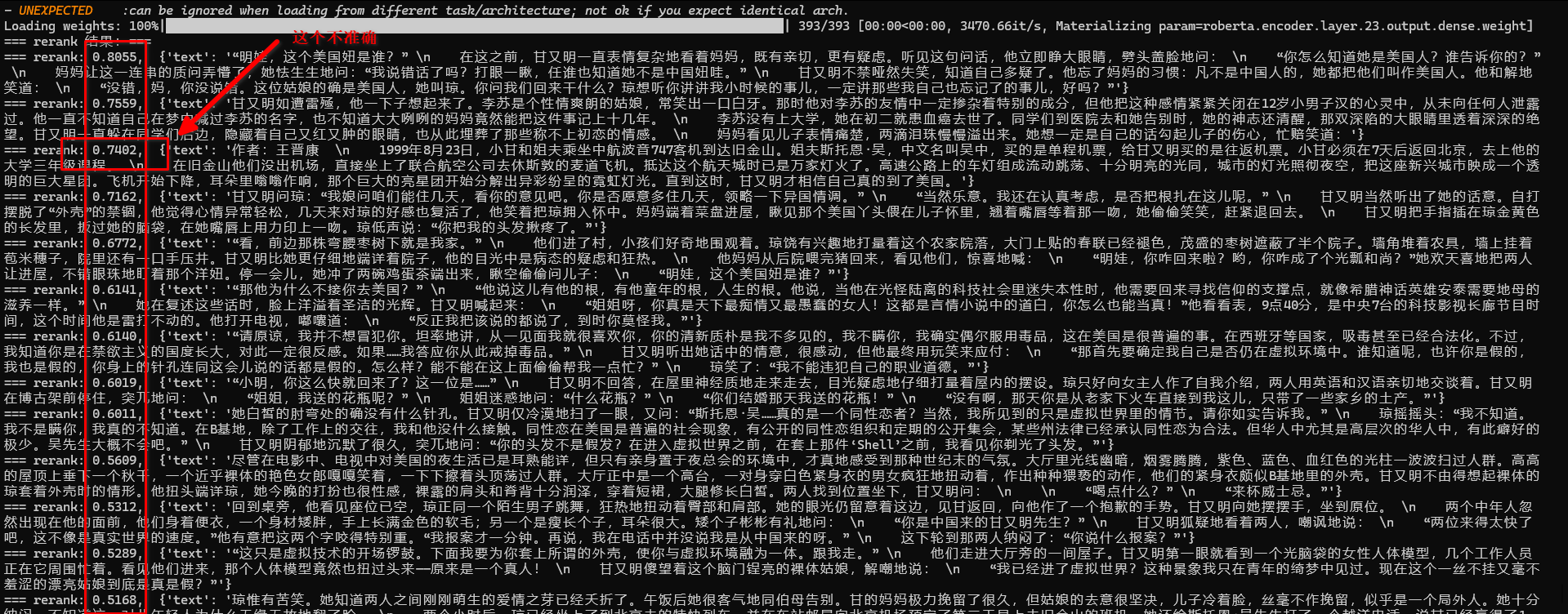
这里都是参考资料,可以一股脑的喂给LLM
其中的第三个,是甘又明和姐夫的描述,跟问题无关,但是排出来,是跟主角相关;尽管他没回答问题,但是也是属于直接的参考资料。所以出现是合理的。
注意:RAG结果不等于 最终结果, 最终结果需要由LLM自行判断的。(它会直接抛弃 上面跟姐夫的那段描述)